
เมื่อคืนวันจันทร์ที่ผ่านมา xAI ของ Elon Musk ได้เปิดตัว Grok 3 ซึ่งเป็นแชทบ็อต Grok เวอร์ชันที่สาม เช่นเดียวกับ Grok เวอร์ชันก่อนหน้า Grok 3 อ้างอิงถึงกลุ่มของ Large Language Model (LLMs) แต่แตกต่างจากแชทบ็อตเวอร์ชันก่อน ๆ xAI เรียกมันว่า "AI ที่ฉลาดที่สุดในโลก" และเชื่อว่ามันเป็นรุ่นที่ดีที่สุด
รายละเอียด: Musk กล่าวว่า Grok 3 ได้รับการพัฒนาด้วยพลังการประมวลผล "10 เท่า" ของ Grok 2 โดย Grok 3 ได้รับการฝึกฝนที่ศูนย์ข้อมูล Memphis ของ xAI ซึ่งมี GPU ประมาณ 200,000 ตัว
“Grok 3 มีความสามารถมากกว่า Grok 2 เป็นอย่างมาก” เขากล่าวระหว่างการสาธิตแชทบ็อตแบบไลฟ์สตรีมเมื่อวันจันทร์ “[มันคือ] AI ที่แสวงหาความจริงสูงสุด แม้ว่าความจริงนั้นบางครั้งจะขัดแย้งกับสิ่งที่ถูกต้องทางการเมือง”
และสอดคล้องกับแนวอุตสาหกรรมที่ได้รับความนิยมมากขึ้น Grok 3 ถูกสร้างขึ้นโดยการใช้การเรียนรู้แบบเสริมกำลังกับโมเดลที่ได้รับการฝึกฝนล่วงหน้า Jimmy Ba หัวหน้าฝ่ายวิจัยของ xAI กล่าวระหว่างการสาธิตว่า “การฝึกฝนล่วงหน้าไม่เพียงพอที่จะสร้าง AI ที่ดีที่สุด AI ที่ดีที่สุดจำเป็นต้องคิดเหมือนมนุษย์”
ดังนั้น ส่วนหนึ่งของตระกูลโมเดล Grok 3 จึงรวมถึงโมเดล 'การให้เหตุผล' ซึ่งคล้ายกับ o-series ของ OpenAI หรือ R1 ของ DeepSeek ซึ่งใช้การให้เหตุผลแบบ Chain-of-Thought ระหว่างการอนุมานเพื่อตอบคำถามได้ดีขึ้น xAI ยังประกาศเปิดตัว 'agent' ตัวแรก ซึ่งเป็นเครื่องมือวิจัยที่เรียกว่า "Deep Search" ซึ่งเป็นการเล่นคำที่ชัดเจนใน Deep Research ของ OpenAI
เช่นเดียวกับ OpenAI มัสก์กล่าวว่า “xAI กำลัง 'บดบังแนวคิดบางอย่าง' เพื่อไม่ให้โมเดลของเราถูกลอกเลียนแบบในทันที มีอะไรมากกว่า 'แนวคิด' ที่แสดงให้เห็น"
ดังนั้น เราจึงมี Grok 3 ปกติ, Grok 3 mini, Grok 3 Advanced Reasoning และ Grok 3 Deep Search ซึ่งเป็นกลุ่มผลิตภัณฑ์ที่มีให้บริการผ่าน X หรือผ่านการสมัครสมาชิกแยกต่างหากโดยตรงไปยังเว็บไซต์หรือแอป Grok ผลิตภัณฑ์เหล่านี้หลายรายการยังอยู่ในขั้นทดสอบเบต้า แม้ว่า Musk กล่าวว่าทีมงานของเขาจะปรับปรุงการจัดส่งอย่างต่อเนื่อง โดยจะมีโหมดเสียงมาถึงภายในหนึ่งสัปดาห์

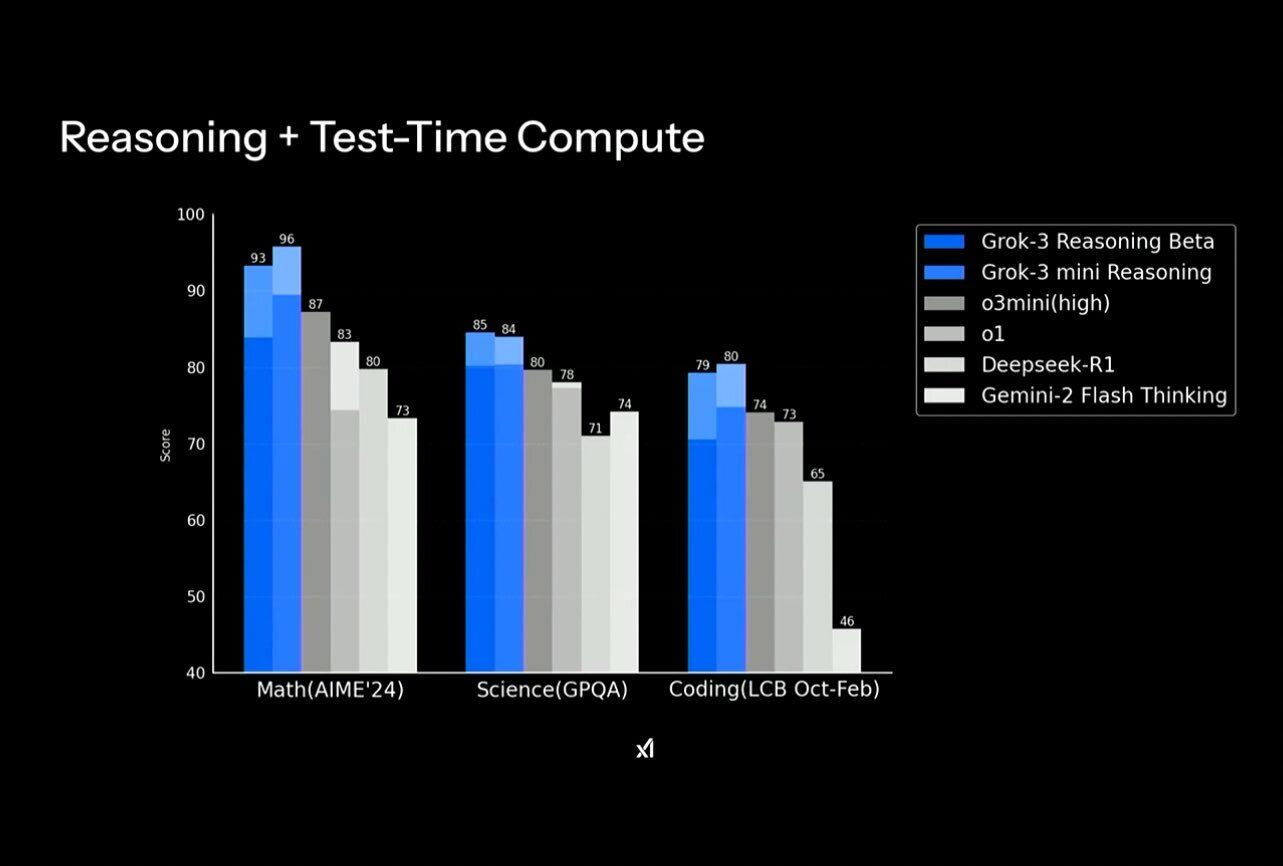
เกณฑ์มาตรฐาน: ตามที่ทีมงานกล่าว Grok 3 เอาชนะคู่แข่งทั้งหมดในเกณฑ์มาตรฐานจำนวนหนึ่ง โดยครองตำแหน่งสูงสุดในเกณฑ์มาตรฐาน "chatbot arena" ที่ได้รับความนิยมด้วยคะแนน 1400 ในขณะเดียวกันก็เอาชนะ OpenAI, DeepSeek, Google และ Anthropic ในด้านคณิตศาสตร์ การเข้ารหัส วิทยาศาสตร์ และเหตุผล เกณฑ์มาตรฐาน
แต่ข้อมูลเหล่านี้ยังไม่ได้รับการตรวจสอบอย่างอิสระ ดังนั้นจึงไม่มีความหมายอะไรมาก แม้จะนำข้อมูลเกณฑ์มาตรฐานมาพิจารณา Grok ก็มีประสิทธิภาพเหนือกว่าคู่แข่ง แต่ด้วยส่วนต่างที่น้อยมาก ซึ่งเป็นสิ่งที่น่าสังเกตเมื่อพิจารณาจากข้อเท็จจริงที่ว่า xAI สร้าง Grok ด้วย "การฝึกมากกว่าโมเดลที่ดีที่สุดในปัจจุบันถึง 10 เท่า" ตามที่วิศวกรซอฟต์แวร์ Paul Klein เขียน “เมื่อทุกคนบอกว่าพวกเขา (ล้ำสมัย) ในการประเมิน คุณก็เริ่มตั้งคำถามกับการประเมิน”
สิ่งอื่น ๆ ที่ควรทราบ: Musk กล่าวว่า xAI จะเปิด Grok 2 แบบโอเพ่นซอร์สในอีกไม่กี่เดือนข้างหน้า หลังจาก Grok 3 มีความเสถียร เขายังกล่าวอีกว่าบริษัทได้เริ่มดำเนินการในกลุ่มศูนย์ข้อมูลแห่งต่อไป ซึ่งจะมีความต้องการพลังงานมากกว่าคลัสเตอร์ปัจจุบันถึงห้าเท่า (ประมาณ 1.2 กิกะวัตต์)
Andrej Karpathy อดีตผู้อำนวยการฝ่าย AI ของ Tesla ใช้เวลาในการทดสอบ Grok 3 และพบว่าโมเดลนี้ “มีความสามารถอยู่ในระดับ o1-pro และเหนือกว่า DeepSeek-R1 แม้ว่าแน่นอนว่าเราจำเป็นต้องมองไปที่การประเมินจริง ๆ”
Karpathy กล่าวเสริมว่าโมเดลนี้ “น่าทึ่ง” เมื่อพิจารณาจากเวลาอันสั้นที่ xAI ใช้ในการสร้างมันขึ้นมา Karpathy ตั้งข้อสังเกตว่า “โมเดลต่างๆ เป็นแบบสุ่มและอาจให้คำตอบที่แตกต่างกันเล็กน้อยในแต่ละครั้ง และมันยังเร็วมาก ดังนั้น เราจะต้องรอการประเมินอีกมากมายในช่วงสองสามวัน/สัปดาห์ข้างหน้า”
ดูเหมือนว่าจะเป็นโมเดลที่ดี แต่สิ่งที่น่าประทับใจที่สุดคือความเร็ว
ความเห็นของ THE DEEP VIEW
ทุกอย่างดูเหมือนจะเท่าเทียมกัน
ผมคิดว่ามันน่าสังเกตอย่างไม่น่าเชื่อว่า ด้วยปริมาณการคำนวณที่ xAI กำลังเผชิญอยู่นั้น มันทำงานได้เกือบเท่ากับ (หรืออาจจะสูงกว่าเล็กน้อย) สิ่งที่ล้ำสมัย ซึ่งไม่สอดคล้องกับแนวคิดที่ว่าการปรับขนาดการคำนวณเป็นสิ่งที่คุณต้องทำ ทั้งหมดที่ต้องทำเพื่อสร้างแบบจำลองที่ทรงพลังยิ่งขึ้น
ผมยังพบว่าเป็นที่น่าสังเกตว่าอุตสาหกรรมทั้งหมดดูเหมือนจะติดอยู่บนเส้นทางเดียวกัน — 'Agent' การวิจัย การใช้เหตุผลแบบ Chain-of-Thought เพื่อเพิ่มการคำนวณเวลาทดสอบ การเรียนรู้แบบเสริมกำลัง โมเดลขนาดใหญ่ที่สร้างจากข้อมูลที่รวบรวมจากอินเทอร์เน็ต ฯลฯ ไม่มีอะไรที่แตกต่างอย่างมีนัยสำคัญระหว่างสิ่งนี้กับโมเดลอื่น ๆ ในตอนนี้
Deep Search ของ xAI หรือ Deep Research ของ OpenAI หรือ Deep Research ของ Perplexity … o3 ของ OpenAI หรือ R1 ของ DeepSeek หรือ Flash Thinking ของ Google หรือ Claude ของ Anthropic หรือ Grok 3 ของ xAI สิ่งที่คุณมีคือบริษัทที่ได้รับทุนจำนวนมากซึ่งโดยพื้นฐานแล้ว ผลิตผลิตภัณฑ์เดียวกัน ด้วยบรรจุภัณฑ์ที่แตกต่างกัน ซึ่งเป็นประเด็นที่นักลงทุนดูเหมือนจะไม่เข้าใจ
ดูเหมือนว่าไม่มีห้องปฏิบัติการรายใหญ่แห่งใดที่กำลังดำเนินการตามแนวทางเฉพาะหรือแอปพลิเคชันเฉพาะ ทั้งหมดเป็นแชทบ็อตและ 'Agent' พร้อมหมายเหตุว่าคุณควรเพิกเฉยต่อภาพหลอนและใช้งานต่อไป เราเข้าสู่การแข่งขันนี้มาสองปีแล้ว และเรายังไม่มีแอปนักฆ่า (ที่ไม่ใช่แชทบ็อต) เราแค่มีบริษัทต่างๆ ที่ถูกล็อคไว้ในการแข่งขัน ด้วยมาตรฐานและขนาด ซึ่งหมายถึงศูนย์ข้อมูลมากขึ้นและประสิทธิภาพลดลง ศูนย์ข้อมูลเมมฟิสที่ Musk ภูมิใจมากได้มีส่วนทำให้เกิดปัญหามลพิษทางอากาศของเมืองอย่างเห็นได้ชัดมาเป็นเวลาหลายเดือน และเห็นได้ชัดว่าทั้งหมดนี้ทำให้ Grok 3 ได้คะแนน 1402 จาก 1385 ของ Gemini ใน Chatbot Arena …
ตามปกติ เราไม่ทราบข้อมูลการฝึกอบรม เราไม่ทราบรายละเอียดเกี่ยวกับสถาปัตยกรรมของโมเดลหรือระบบ เราไม่ทราบความเข้มของพลังงานและการปล่อยก๊าซคาร์บอนที่เกี่ยวข้องกับทั้งการฝึกอบรมและการใช้งานโมเดล และเราไม่มีการตรวจสอบคะแนนมาตรฐาน
ดังนั้น อีกวันหนึ่ง อีกแบบจำลองหนึ่ง
การแข่งขันดำเนินต่อไป




